
In Defense of Version Control
git push medium article
I just completed this Udacity course “How to Use Git and GitHub” by Sarah Spikes and Caroline Buckey, and I just can’t wait in leveraging the power of version control in developing my current projects. I’m starting to realise that I was late in realising the importance of version control.
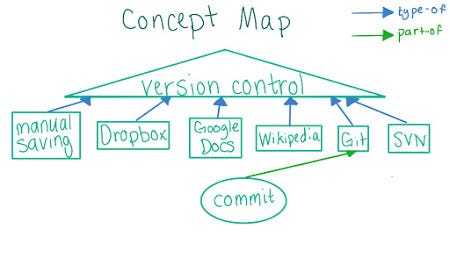
Above is one of the early concept maps in the Udacity course.
Here I try to provide sufficient motivation for using a version control system (VCS) for your projects, and guide you a bit about how people use a VCS called Git, which was Linus Torvalds’ another gift to humanity. However, no in-depth programming knowledge is a prerequisite, and there’s no code mentioned at all in this post (you have the course I mentioned above for learning the specifics), so don’t be afraid! There are just a handful of commands mentioned. And of course, you can develop your projects without version control, but with it, you can do so in a more free and versatile manner. Once you get into using version control, you’ll be amazed by its power and would wonder how you used to do develop your stuff without it!
So what exactly is version control (or source control or revision control)? To put it simply, version control means to track your files. While you can see some obvious utilities like backups, access to the history of your files and so on, version control is more than just that, as you’ll soon discover. But one may point out some disadvantages as well. A plain to see drawback is larger memory footprint. However, the footprint usually isn’t as large as one might think, and in my opinion the power you get is priceless compared to the memory version control consumes.
Since we develop most of our projects incrementally, adding or changing content is a routine and is spread over multiple days and files. Thus, what if we discover later that the code we added last Friday actually contained a not-so-easy-to-be-fixed-bug? Wouldn’t it be nice if we could somehow time travel and get back to the state of code before last Friday, so that we (and other users) can still use the code without running into problems? Version control allows us to precisely accomplish this. Furthermore, it still allows access to the new code so that we can review and fix it, while our “production code” (one without bug(s)) is still intact. The bug may span multiple files/scripts, so tracking multiple files would also be desirable, and yes, version control provides that as well.

Image source: http://smutch.github.io/VersionControlTutorial
By the way, version control systems don’t have to be necessarily related to program scripts and they’re not just used by developers. Version control manifests over a large domain. In fact, this very post has its own revision history, which I can use for many purposes. for example, I can get back a paragraph I deleted a few days ago just by going to the saved part which had it. These saved parts are like individual snapshots of the post over the course of its development. (In tech-speak, we call such snapshots “commits”.) Commits can also be thought of as checkpoints over the course of development of a project. Time Machine (accurate name, right?), Apple’s backup system for Macs, can also be considered a version control system. It has become more of a philosophy than technology. Dropbox, Google Docs, Git (of course!), manual backups…the list is endless — all have version control in some form. If we think about it, even undo and redo — the actions we use countless times every day, are tiny version control systems! So ubiquitous!
Speaking of utilities mentioned above, we know that they do automatic backups of our work. However, these allow only for online backups and have limited offline support (except Time Machine). But there are tools out there which provide offline as well as manual backups, and other additional utilities. One such popular tool is Git, which is sort-of fine tuned for software development. Speaking in this context, usability of manual “commits” is subject to self-discipline. One may not make commits for a long period of time, thereby not saving important large changes. Or s/he may commit too often, thereby making version history more cluttered. However, manual commits give much more flexibility over automatic saving if the user commits wisely. One can commit whenever a logical unit has been added/changed. The user should commit whenever s/he feels appropriate, but only significant commits allow for convenient going through of revision history. Cons of using automatic saving are that they may lead to potentially unnecessary saves and can make your history cluttered. Many of the saves may not even make sense and compile. Manual commits work great in that they avoid such bad stuff to happen, if performed wisely.
Some systems, like Git, also allow to commit multiple files in one go. Here, it should be noted that Git was designed keeping programmers in mind. In programming, distributing your work across different files is common. So it often happens that you use code from one file in another file (common with modular programming). Thus, changing code in one file can directly effect behavior of another file, and can consequently require changes in the other file. So a commit should have the capability to save multiple files. If one edits a file, then makes a commit, the other file may not compile properly (as it requires corresponding adaptive changes). On the other hand, Google Docs saves files individually because changes in one document are generally not linked to changes in other documents.

Version control can be difficult to understand, but with patience and persistence, you can and will eventually master it.
Image Source: https://xkcd.com/1597/
Quite non-intuitively, version control also boosts your confidence and risk-taking instincts. It gives more confidence in making larger changes that could break things, because even if the changes I made break the program I’m working on, I can easily get back to an earlier, working version of my repo as I have access to the history of my files. Also, here comes another jargon — repo (or more formally, repository). To put it plainly, a repository is just a collection of files you want to track together. It’s just like a folder or directory on your computer which contains a bunch of files (and potentially other subfolders or subdirectories). However, in addition to these contents, a repository also contains some metadata about the history of these contents. With Git, you type at terminal “git init” in your working directory and boom! Your directory becomes a repository! Now you can track the changes of any file inside this directory using Git; it will log the commits you make on the files changed. Furthermore, you can also choose which files to track and which files not to track. Isn’t that awesome?
I mentioned earlier that you can save multiple files across a commit. Well, how exactly does that happen? What makes this possible is the staging area. Working directory contains files which are both being tracked and not being tracked. It’s just a usual directory. However, staging area contains only those files which are to be tracked. Its utility is that it allows us to have a place to check that we are doing what we really intend to do before creating a commit. In other words, staging area is a stepping stone between a bunch of changed files in a directory to the commit which saved the changes in those files. It really helps in making one commit per logical change.
So far, we’ve talked about making changes and saving them as commits so that you have a nice chain of commits which allows better and effective tracking, among other things. But what if you want to work on a new feature (maybe like extending your app service to another country), while keeping the existing code intact? This is where branches come into play. In this context, a branch is simply just another chain of commits. This chain may have a common “ancestor” or commit with another chain of commits(i.e., another branch). Thus, what we have is two different chains of commits, each representing different, but parallel versions of our code. Branches help in keeping our history organized because they allow us to separate out different featured versions so that we can focus on any specific version at one time without affecting the other versions. This allows for keeping the history of each version relevant and to the point, without interfering other versions’ histories. Thus, branches allow us to maintain multiple parallel versions of our code, each version representing something or the other. Usually, in Git, your “main” branch which contains production code is called “master”.
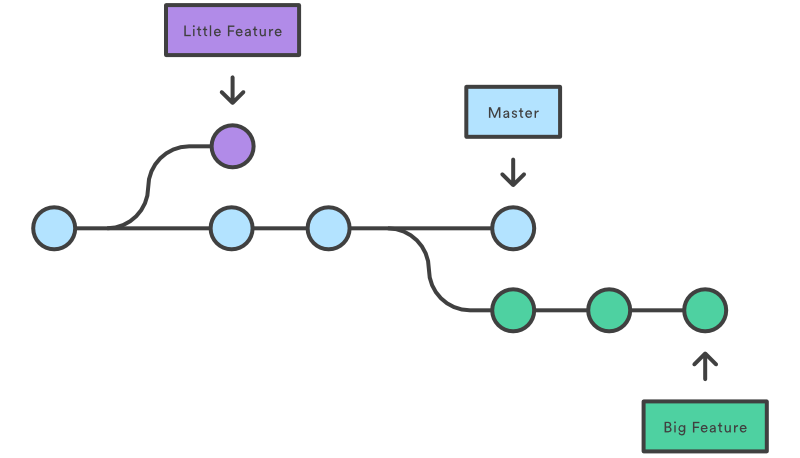
Three branches here — circles represent commits. All branches have their respective heads (rightmost circles) which represent latest commits and all the branches began took off from a single commit (the earliest, leftmost one). Before that, there was just one branch.
Image source: https://www.atlassian.com/git/tutorials/using-branches
In Git, we can visualise branches in our repository as diagrams. Diagrams help in getting an idea of how the history of our repository looks like. They also give us a sense of the development activities taking place in our repo. Diagrams provide a “big picture” view of our repo, showing the activity all around, not just the activity of our checked out branch (i.e, the branch we’re currently working on). Branches are also super useful when we’re collaborating with others. It is possible that other people have access to your repository for collaboration — maybe by sharing the same computer, or as is more common these days, by having access to a copy of your repository on the Internet (which is known as the “remote” of your repo). “git push remote master” is the command you use to upload the changes (in this case the changes made in the master branch) in your local repo — the repo on your computer, to the remote counterpart of it (hence “git push medium article” in the subtitle). But multiple people committing on the same master branch may create confusion and it might also happen that the code on master breaks. But wouldn’t it be so convenient if my collaborators work on different branches? There would be less conflicts and the production code on master branch would be safe from potential bugs. However, it’s okay to commit directly on master when a feature or fix is small and we are quite confident that it would neither break our master code nor cause significant problems with other collaborators.
But consider that we just completed working on a big feature and now we want to officially add it to our existing code. We did use a different branch for working on this feature, but now we want to combine the existing production code on master branch with the code containing the new feature. How do we do this? We merge the master branch with the featured branch. In case there’s a conflict (like apart from adding code, the featured branch also changed some of the previous code which master branch still uses), Git will report the conflict and then it’s the collaborators’ duty to resolve the conflicts. No merging happens util the conflict is resolved. But once it is, the branches get merged into a new commit which contains code from both the repositories. We can choose what label we give to this commit. By label, I mean we can choose what branch this commit should represent — the master branch or the featured branch.
Furthermore, while we are still working on the featured branch, merging allows us to keep up with the changes getting commited on the master branch. To do so, we can periodically merge the master branch into the featured branch and label the resulting commit as being part of the featured branch. This does not affect the existing master branch at all — people can still commit changes to it and we can still merge those changes into the featured branch.
I hope that gives you a gist of how you can use version control (or Git specifically) to track your files and collaborate with people on your or others’ projects. I would also like to add that the philosophy of version control can be extended beyond software development. However, using Git for general-purpose version control (which boils down to simply backing up your content) wouldn’t be a good idea. It would be more like using a sledge hammer to pin down a nail 🙂. Almost everyone uses version control in some form or another, and most take it for granted. But yes, it indeed helps to keep things organized and above all, it makes our lives easier (and perhaps fun).
A natural extension to learning version control is learning collaboration using a site like GitHub, but I think it deserves a separate discussion. Here I tried to provide you an abstracted-out view of version control, and obviously I didn’t cover everything. If you want to learn the specifics of Git, definitely check out the Udacity course I mentioned, or see the official Git website.
Kudos if you made this far!
I’m new to blogging, so constructive criticism is not only welcomed, but very much wanted!
Hacker Noon is how hackers start their afternoons. We’re a part of the @AMI family. We are now accepting submissions and happy to discuss advertising & sponsorship opportunities.> If you enjoyed this story, we recommend reading our latest tech stories and trending tech stories. Until next time, don’t take the realities of the world for granted!
