
Apache Hive (A Complete Journey) Series-1 of 3

Apache Hive
Apache Hive
The Apache Hive ™ data warehouse software facilitates reading, writing, and managing large datasets residing in distributed storage using SQL (Standard Query Language).
Where does Hive Fall in the Stack?
From the figure below, we can see that Hive is more of an abstraction layer lying on top of YARN Map-Reduce 2. Moreover, note that Hive and Pig lie in same horizontal stack.
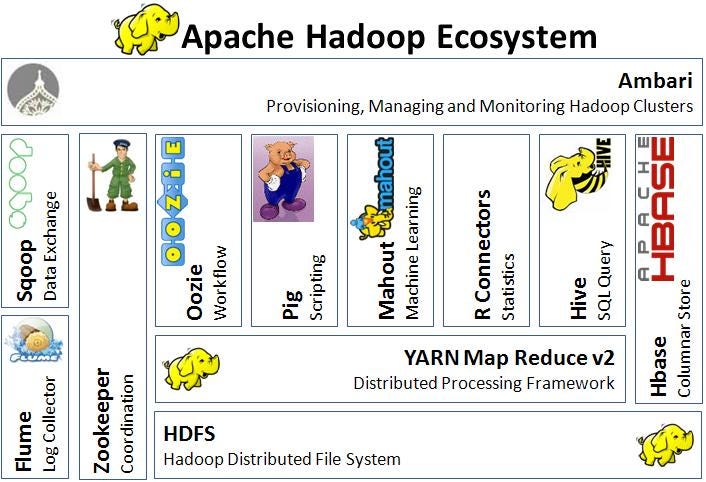
Architecture
As we see that Hive is an abstraction on top of Hadoop Map-Reduce jobs. So the underlying structure is same i.e. Hive run on top of Hadoop.
So, Hive mainly consists of two components i.e. Hive and Hadoop.
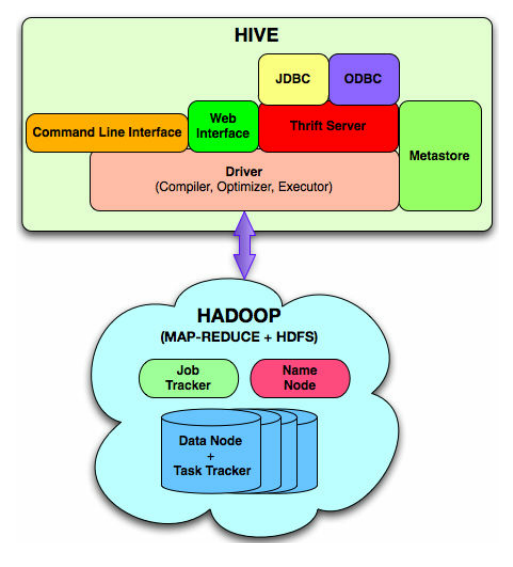
Hadoop Components
Hadoop Key components are Yarn and HDFS. Yarn is the resource manager, whereas HDFS is the distributed file system of Hadoop.

The picture is showing how data is distributed in different nodes.
Hive Components
- External Interfaces- CLI, WebUI, JDBC, ODBC programming interfaces
- Thrift Server — Cross Language service framework .
- Metastore — Meta data about the Hive tables, partitions
- Driver — Brain of Hive! Compiler, Optimizer and Execution engine

Hive Importance
Data Analysts with Hadoop (Uncomfortable)
Mostly Data analysts feel uncomfortable while working on Hadoop due to the coding nature of Hadooop (Since for each analysis you have to write customize map-reduce jobs).

Limitations of Hadoop
The biggest limitation of Hadoop is that one have to use M/R model (Map-Reduce Model). Other limitations are as stated below:
* Not Reusable
* Error prone
* Multiple stage of Map/Reduce functions for complex jobs.
*It’s just like asking a developer to write physical execution plan in the DB.
Hive Data Model
- Tables
- Partitions
- Buckets
Tables
Analogous to relational tables. Each table has a corresponding directory in HDFS. Data serialized and stored as files within that directory.
Partitions
Each table can be broken into partitions. Partitions determine distribution of data within subdirectories.
Example
CREATE_TABLE Sales (sale_id INT, amount FLOAT)PARTITIONED BY (country STRING, year INT, month INT)
So each partition will split out into different folders like:
Sales/country=US/year=2012/month=12

Buckets
Data in each partition divided into buckets based on a hash function of the column. Each bucket is stored as a file in partition directory.
Example:
H(column) mod NumBuckets = bucket number
H(column) mod NumBuckets = bucket number
Comparison between Hive and Pig since they both fall in same horizontal block of the stack.
Similarities
Both High level Languages which work on top of map-reduce framework. Since, both use the underlying HDFS and map-reduce they both can coexist.
Differences
- Language
Pig — is a procedural ; (A = load ‘mydata’; dump A)
Hive — is Declarative (select * from A) - Work Type
Pig — more suited for ad hoc analysis (on demand analysis of click stream search logs)
Hive — a reporting tool (e.g. weekly BI reporting) - Users
Pig — Researchers, Programmers (build complex data pipelines, machine learning)
Hive — Business Analysts - Integration
Pig — Doesn’t have a thrift server(i.e no/limited cross language support)
Hive — Thrift Server - User’s Need
Pig — Better development environments, debuggers expected
Hive — Better integration with technologies expected(e.g JDBC, ODBC)
Hive Pros, Cons and Improvements
- Boon for Data Analysts
- Easy Learning curve
- Completely transparent to underlying Map-Reduce
- Partitions(speed!)
- Flexibility to load data from localFS/HDFS into Hive Tables
- Extending the SQL queries support(Updates, Deletes)
- Better debug support in shell
Where Hive is useful?
Wherever Batch-processing is involved like: Log processing, Text-Mining, Document-indexing, Customer Facing BI,and Predictive Modeling.
Where ain’t useful?
Wherever Online processing involved like: OLTP and Real-time Queries.
Thank you for reading the introductory blog for Apache Hive. Now if you want to try it out. Let’s start with configuring Hadoop first.
Continue to Series Part 2 of 3 .
Configuration Setup
- YARN, Zookeeper, HDFS, Hadoop, Hive Hadoop Blog Link
- Docker Image
- Distributed Setup (single node OR all) Hadoop Blog Link
- Hive Installation Hive Installation Blog Link