
Twitter Sentiment Analysis
Twitter is a popular social network where users can share thoughts. Getting people’s impression on a tweet is actually an awesome idea. I can actually get to know what people think about a particular brand, celebrity, personality.
Getting Twitter data has been made very easy using Twitter API, you can check my first article with UB women publication here on how to setup Twitter application and generate a Consumer Key, Consumer Secret, Access Token, and Access Token Secret.
consumerKey = ‘XXXXXXXXXXXXXX’
consumerSecret = ‘XXXXXXXXXXXXXX’
accessToken = ‘XXXXXXXXXXXXXX’
accessTokenSecret = ‘XXXXXXXXXXXXXX’
I’ll be using Tweepy to access Twitter data. Tweepy is a python library for accessing the Twitter API. The next step is API authentication, Authentication API enables you to manage all aspects of user identity when you use Auth0.
auth = tweepy.OAuthHandler(consumerKey, consumerSecret)
auth.set_access_token(accessToken, accessTokenSecret)
api = tweepy.API(auth)
You can now access Twitter data; I’ll be using api.search() from Tweepy to get my search, I am also using Cursor module,tweepy.Cursor() handles pagination so I can specify the number of tweets I want to get.
tweets = tweepy.Cursor(api.search, q=’davido’).items(200)
Now that I have my tweets ready I can get several attributes from the tweet, I can get tweets from a particular region, language, time a tweet was created. What I need for this project is tweets written in English, I am getting the text body of the tweet using tweet.text.

I can start preprocessing my text by applying various preprocessing techniques like tokenization and lemmatization. You can check my article on text wrangling here. I’ll be using NLTK for preprocessing. NLTK(Natural Language Processing toolkit) is a tool for building Python programs to work with human language data.
The first thing I’ll be doing is to remove unwanted symbols using regex expression, tokenize data, remove common words and turn each word to its root level by lemmatizing the text. Lemmatization is the process of turning a text to its root word. Let’s have a view of our clean data.

root_text
After getting our data we need to classify tweets into positive and negative. In this series, I’ll be using TextBlob to classify tweets into different sentiments (positive, negative ). Texblob is a library for processing textual data, It provides a simple API for diving into common natural language processing tasks.

classify tweets into positive and negative
Now we are done with our sentiment analysis, the next step is to save and read data.

From here we can visualize, I am visualizing so I can understand the data better.
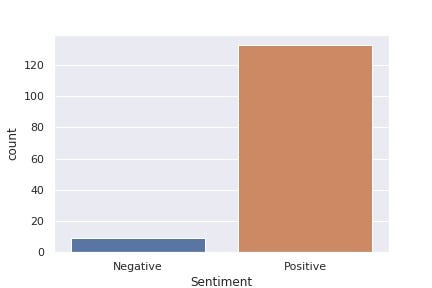
Conclusion:
Thanks for reading, I love feedbacks please let me know what you think. You can access the full code here.
Resources:
https://auth0.com/docs/api/authentication#post-passwordless-verify
Tweepy Documentation - tweepy 3.5.0 documentation
_Edit description_tweepy.readthedocs.io
https://textblob.readthedocs.io/en/dev/quickstart.html#sentiment-analysis