
Hunting Intermittent Tests
There’s a sad time in testing land when you have a test suite that you can’t rely on. Instead of running a suite and merging if it passes, you have to glance over the failed tests and say “Oh that one… that test is flaky.”

Then it becomes a class of tests, “oh we can ignore Elasticsearch tests.” Eventually we stop trusting the build and just merge it. Because it’s probably the Elasticsearch test that failed. At least I think that’s what my email said:

The builds all start to blur together.
Enter the Huntsman
Obviously we don’t want a test suite that we don’t trust. It’s just a 10-20 slowdown that gives no value if we don’t heed it’s wisdom. If it’s spouting half-truths we’ll need to route them out.

The Huntsman
So I decided to hunt down intermittent tests. Qualitative judgements are hard to deal with:
- The test suite is unreliable.
- Elasticsearch is flaky
- My cat is mean to me
While all of these statements might be true, it can be hard to fix them and actually feel like your fix did anything.
Measure Up
So time to measure. The nice property of “intermittent” tests is that they aren’t prompted by a code-change. They just fail seemingly at random. So I created a branch off of our master called circle-ci-test. I figured a good test of how intermittent our tests were would be to keep running the tests and we could look either in CircleCI or push the result status to Datadog.
Here’s how I did that:
We do a few things:
- Check if we’re busy building other things.
- Trigger the build
- While the build is triggered see and log the status of the last build to Datadog.
The result of step three is this chart.
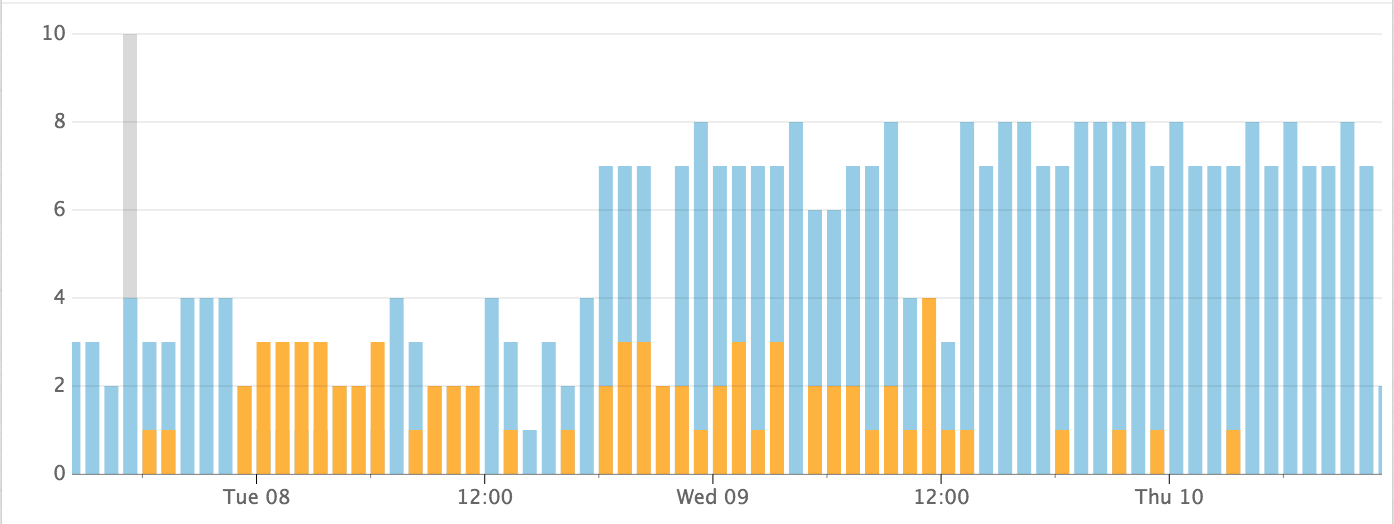
Orange builds are bad, blue builds are good.
Sometime after noon our team fixed some tests and it made things happen less frequently.
Test just what you need
In our particular situation we had issues with Elasticsearch. Our platform is Rails backed by Postgres and Elasticsearch, what we discovered is we had some tests that relied on Elasticsearch being present, but the tests ended up querying before Elasticsearch was ready to serve.
We ended up taking creating an index, but never adding anything to the index. That’s what ended up throwing us off. We used some well placed testing doubles to eliminate the need for Elasticsearch:
dbl = double(:total => 0, :empty? => true, :map => nil)
allow(Search).to receive(:perform_search).and_return(dbl
Our test never looked at the results, it just verified that certain rendering attributes happened.
Test Ordering
Some issues were very intermittent — 2–3% of our builds would fail. We were pretty sure that test ordering was part of our problem.
I ran into similar issues at Pinterest when I massively parallelized the test-suite. At Pinterest we had no database backing for our tests, it was an issue with mocking and clean-up. In this case we were dealing with artifacts leftover in the database.
rspec left a clue:
Randomized with seed 7918
I could run
rspec --seed 7918
to run the tests in the same order.

Combined with the bisect option I was able to narrow the set of tests by quite a bit, but there was an issue with bisect. Much of our intermittency now was caused by data remaining in the database between test runs. These never were cleaned up, even after test-runs. So bisect served as a guide.
So fresh and so clean
We used the Database Cleaner gem to clean our database between test runs. It worked great in most cases, but there were a few times it was circumvented. We enabled it using before and after statements, but if someone used around in a test that would circumvent the transaction that the gem set.
I upgraded the gem and followed the suggested method of using config.around to always run tests using the DatabaseCleaner.cleaning context. This looked clean, but many things broke because upgrades. Once we cleared out the issues we had a build that’s been fairly clean for the last four hours.
Competing Philosophies
Ideally we could run each test in an isolated but homogenous environment. No test would interfere with one another and everything would be repeatable. The cost, however, is speed and processing power. If we could run 1000 tests all at the same time the overhead wouldn’t hurt, but we can’t do this yet.
So the world we live in means tests need to play nice. Right now the road we’ve taken is that each test assumes a clean state, and relies on the previous test to clean up after itself. This is fine, but it can make for a brittle test suite.
A competing philosophy might be one that requires us to clean up before we run our test as required. For example, a test that states:
- Adds two users, Trish and Hope to the system
- Verify that in a list of all the users only Trish and Hope are present
Can only work if we assume a clean state. In a world of badly behaving tests that leave artifacts around we might need to add a step:
- Remove all users.
The tradeoff is that we pay a cost to remove all users even if there aren’t any users to remove.
We’ll stick with the former philosophy for now until it becomes unbearable.
There really isn’t any magic with intermittent tests. All of our failures had logical reasons for failing. If you are plagued with this issue, the first step is to collect metrics around your tests, just as you might collect business or operational metrics.
After you collect data you’ll need to look at each test individually. The issues I’ve run into were:
- Testing systems which weren’t warm (Elasticsearch)
- Database not being cleaned
- Test ordering being confusing.
- Mocks not clearing themselves.
Good luck.
If you liked this post you might also enjoy this one:
Saving 60 engineer hours a day
_How I cut down 30+ minute builds to 2 minutes_medium.com