
Naive Bayes Classifier: A Geometric Analysis of the Naivete. Part 1
The curse of dimensionality is the bane of all classification problems. What is the curse of dimensionality? As the the number of features (dimensions) increase linearly, the amount of training data required for classification increases exponentially. If the classification is determined by a single feature we need a-priori classification data over a range of values for this feature, so we can predict the class of a new data point. For a feature with 100 possible values, the required training data is of order O(100). But if there is a second feature as well that is needed to determine the class, and has 50 possible values, then we will need training data of order O(5000) – i.e. over the grid of possible values for the pair "". Thus the measure of the required data is the volume of the feature space and it increases exponentially as more features are added.
But is this always this bad? Are there some simplifying assumptions we can make to decrease the amount of data required, even while keeping all the features? In the above example we said we needed training measurements of order O(5000). But naive bayes classifier needs measurements of order only O(150) – i.e. just a linear increase, not an exponential one! That is fantastic but we know there is no free lunch and naive bayes classifier should be making some simplifying (naive?) assumptions. That is the purpose of this post – examine the impact of naivete in the naive bayes classifier that allows it to side-step the curse of dimensionality. On a practical note, we do not want the algebra to detract us from appreciating what we are after, so we stick to 2 dimensions and 2 classes and .
Decision Boundary
Decision boundary is a curve in our 2-dimensional feature space that separates the two classes and . In Figure 1, the zone where y–f(x)>0 indicates class and y–f(x)<0 indicates . Along the decision boundary the probability of belonging to either class is equal. Equal probability of either class is the criterion to obtain the decision boundary.

Figure 1. The decision boundary separates the two classes and in the feature space. For points on the decision boundary, the probability of belonging to either class is the same.
The objective of this post is to analyse the impact of nonlinearities in the decision boundary and the coupled issues that arise from unbalanced class sizes. The overall outline for this post is as follows.
- Pick an exact functional form for the true decision boundary.
- Obtain a closed-form solution to the decision boundary as predicted by naive bayes classifier
- Analyse the impact of class sizes on the predictions
- Obtain the asymptotic behavior when one of the classes overwhelms the other
- Repeat 1 thru 4 when is linear and nonlinear.
The content of the post is somewhat academic as with real data we do not know the true decision boundary, have to deal with data noise, and do not know which features are actually responsible for classification we seek etc… But the point here is to understand the impact of naivete assumption in an idealized setting so we would be better equipped to apply and interpret the naive bayes classifier for real data.
1. Naive Bayes Classification
Naive bayes classification is based on Bayes rule that relates conditional and marginal probabilities. It is well described in literature so we simply write the equations down for a 2 class ( and ) situation with 2 features .
(1) 
For any new measurement we would compute and , as per Equation 1 and pick the class with the larger value. As the denominator is the same it is easier to just compute their ratio so we do not have to evaluate
is the probability for any measurement to fall into the class . It is computed easily enough from the training data as the relative abundance of samples. It is the computation of that is fraught with the challenge of data requirements we talked about. To do it right we need to estimate the joint probability distribution of in each class and that requires training data on a grid of values. That is where the naive part of naive bayes comes in to alleviate the curse of dimensionality.
1.1 The Naive Assumption
If the features were to be uncorrelated, given the class then the joint probability distribution would simply be the product of individual probabilities. That is
(2) 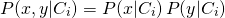
If we make this assumption then we only need to estimate and separately. And that only requires training data on the range of and on the range of – not on a grid of values. Using Equation 2 in Equation 1 we get the ratio of the class probabilities for a new measurement and its class assignment thereof to be as follows
(3) 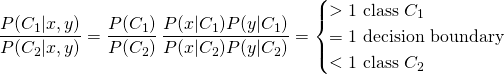
While the naive assumption of uncorrelated features simplifies things, its validity is open to question. If for example in a class, then the probability of finding large values will be higher when is small, and lower when is large. In fact the probability of finding the measurement =0.9,=1.1 in this class will be unity, whereas it would be zero for the measurement =0.9,=1.2. Clearly, the probability distributions of and will not in general be independent of each other and making the naive assumption of independence can lead to incorrect class assignment for new data.
1.2 Deriving and
If we can obtain and as functions of then we have the ratio in Equation 3 as a function of .
Figure 2. Deriving the naive bayes probabilities, given a true decision boundary . To keep the algebra simple, the function is taken to have a simple inverse . The fractional areas of the rectangular strips in a class are indicative of the probability.
Consider Figure 2 where the true decision boundary , splits the feature space into two classes. To keep the algebra at bay, we further take to be explicitly invertible so we can write .The a-priori probability of a class is proportional to its overall size – area in this case.
(4) 
To compute imagine that we discretized the x-axis and picked a small rectangular strip of width δx around as shown in Figure 2. The area of the strip in class divided by the class area would be the probability $P(x|C_i). Likewise for the probability
(5) 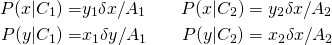
The longer is, the higher the probability of would be. Likewise a larger implies a higher probability for and so forth. Once we appreciate this, the rest is simply geometry and algebra. Combining Equations 4 and 5 with naive bayes classification in Equation 3, we get:
(6) 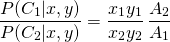
The locus of for which the ratio above equals unity is the decision boundary as predicted by the naive bayes classifier.
(7) 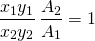
Figure 3. For a point on a linear decision boundary, a geometric proof that: (a) in case of balanced classes and (b) when classes are unbalanced.
For an intuitive understanding of Equation 7 consider the case of a linear decision boundary with equal/unequal class sizes in Figure 3. When class sizes are equal as in Figure 3.1 the decision boundary would be the diagonal, and for every point on the diagonal, the area of the rectangle ABOC equals the area of the rectangle ODEF. But that is nothing but a statement about the equality of and for any point on the diagonal.Thus as per Equation 7 the decision boundary predicted by naive bayes will match the diagonal – the true decision boundary. In Figure 3.2 however, the class sizes are not the same and the areas of these two rectangles do not have to be equal for every point on the separation boundary. So we cannot expect naive bayes to yield the true decision boundary even in the linear case when the class sizes are not the same. We shall verify this again analytically in the next section.
That completes our general method for deriving the decision boundaries as predicted by naive bayes. For the remainder of the post we choose different functional forms for the true decision boundary and contrast that with what we get from naive bayes.
2. A Linear Decision Boundary
We start with the linear case in Figure 4 where a straight line separates the two classes in a rectangular feature space. When equals we get balanced classes.
Figure 4. Evaluating , , and for a linear decision boundary
The class areas , and the lengths , and follow directly from the geometry. Using them in Equation 7 and simplifying we get the decision boundary as predicted by naive bayes to be a hyperbola.
(8) ![\begin{equation*} \frac{q}{y} = 1 + \frac{1}{2b -q} \left[\frac{ab}{x} - q \right] \end{equation*}](http://xplordat.com/wp-content/ql-cache/quicklatex.com-e1127074c66e7659babef22960d18192_l3.png)
With the closed-form solution in hand for the predicted separation boundary, we can look at the impact of class size and asymptotics thereof when the size of class keeps increasing while stays constant. This is achieved through increasing while holding and constant.
2.1 Balanced classes. =
When , the class sizes would be equal and the separation boundary reduces to:
(9) ![\begin{equation*} \frac{q}{y} = 1 + \frac{1}{q} \left[\frac{aq}{x} - q \right] = \frac{a}{x} \end{equation*}](http://xplordat.com/wp-content/ql-cache/quicklatex.com-7f6b21e381ddcea9fd3541d368d119b8_l3.png)
which is the true decision boundary. That is, naive bayes classification will have no error when the classes are separated by straight line and have the same size. This is a rigorous proof of the same geometric argument made in Figure 3.
2.2 Unbalanced classes. Increasing and constant
Figure 5 shows the predicted decision boundaries as is increased (i.e. we drag the top-boundary of the feature space), thus increasing while holding constant. In all the cases the naive bayes predictions start off favoring class (the predicted boundaries are above the true boundary – meaning a preference to classify a true measurement as ) for smaller and switching over to prefer class as increases. It is interesting however that they all switch over at the same point on the true decision boundary.
2.2.1 The switch over point
The switch over point is the intersection of the true decision boundary and the predicted decision boundary. Using in Equation 8 and simplifying we get,
(10) 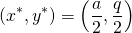
Figure 5. Linear decision boundary. Naive bayes classifier predicts a hyperbola as the class boundary. Only when the classes are balanced does the prediction match the prescribed boundary
The coordinates of this point are independent of – the only variable across the different curves. Hence they all intersect the true boundary at the same point.
2.2.2 The asymptotic boundary:
As increases, the ratio increases. In the limit as goes to infinity, we get the asymptotic prediction boundary .
(11) ![\begin{equation*} \frac{q}{y_{\text{s}}} = 1 + \lim_{b\to\infty} \frac{1}{2b -q} \left[\frac{ab}{x} - q \right] = 1 + \frac{a}{2x} \end{equation*}](http://xplordat.com/wp-content/ql-cache/quicklatex.com-26817d78bc1465a0fc02938785ffaac2_l3.png)
3. A Nonlinear Decision Boundary
We now consider the case in Figure 6 where a parabolic decision boundary separates the two classes.
Figure 6. Evaluating , and for a nonlinear decision boundary
Once again the expressions for , and as functions of follow directly from the geometry. Applying Equation 7 and simplifying we get as a fourth order function of for the predicted decision boundary
(12) 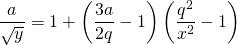
3.1 Effect of increasing and constant
Figure 7. Nonlinear decision boundary. The naive bayes prediction does not match the true boundary even in the case of balanced classes.
Figure 7 shows the predicted decision boundary Vs the true boundary as the class size is varied while holding constant. This is simply done by dragging the right-boundary of the feature space, i.e changing .
Here are a few quick observations that are in contrast with the linear case.
- Even in the case of balanced classes ( i.e. ), the predicted boundary does NOT match the true boundary. This is unlike the linear case as we have seen earlier. Using in Equation 12 we get:
(13) 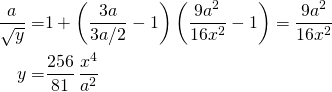
- For small the prediction favors over (the predicted boundry starts off below the true boundary in all cases) but switches over to prefer for larger .
- When is small the predicted boundary is mostly under the true boundary over the range of . For larger the predicted boundary gets steeper and intersects the true boundary earlier and earlier. Thus unlike in the linear case they intersect the true boundary at different points.
- Even while they intersect the true boundary at different points, it is interesting to note that they all intersect each other at a single point. That can be proved of course. The only variable across the different curves is . So all we have to is to find the point of intersection for two predicted boundaries and show that it is independent of . Consider two such boundaries for and . Using Equation 12 at the point of their intersection and simplifying we get,
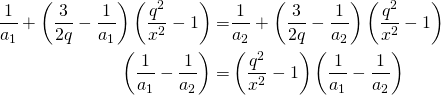
yielding the intersection point to be independent of thus proving the observation.
(14) 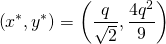
3.2 Asymptotic boundary:
As increases, the area increases. In the limit as goes to infinity, we get the asymptotic prediction boundary .
(15) ![\begin{align*} \frac{1}{\sqrt{y_{\text{s}}}} = &\lim_{a\to\infty} \frac{1}{a} + \left( \frac{q^2}{x^2} - 1 \right) \left[\frac{3 - \frac{2q}{a}}{2q} \right] \\ = & \left( \frac{q^2}{x^2} -1 \right) \frac{3}{2q} \end{align*}](http://xplordat.com/wp-content/ql-cache/quicklatex.com-b227a58dcc2d0825b84b447b992ef107_l3.png)
4. Next Steps
We have derived closed-form solutions to the decision boundaries predicted by naive bayes classifier, when the true decision boundary is known between 2 classes with 2 features. We picked simple linear and nonlinear boundaries and evaluated the impact of class sizes and asymptotics thereof when one class overwhelms the other. The next steps are as follows.
- Obtain the confusion matrix as a function of class size ratio while the total size is remains constant. For example as we vary from 0 to 1 in the Figure 4, the ratio goes from to 0 while stays constant at . The performance of naive bayes classifier gauged via the various metrics coming off of the confusion matrix is of interest in this case.
- Simulate the Gaussian Naive Bayes algorithm as implemented in SciKit to evaluate the additional errors introduced by the gaussian approximation to probability.
- Evaluate naive bayes predictions against other competing classifiers such as logistic regression, neural nets etc…
As this post is getting too long so will take up the above and more in the next post in this series.