
Mastering data structures in Ruby — Hash Tables
A hash table is a data structure optimized for random reads where entries are stored as key-value pairs into an internal array. Since we access elements by hashing their key to a particular position within the internal array, (assuming approximation to uniform hashing) searches run in constant time.
If you have to remember just one thing about hash tables, that thing should be that “a hash table maps a key to an index of an array.”. By doing that you’ll be able to “guestimate” the complexity of operations based on how well arrays would do. For instance, insert, update, read, and delete, are all O(1) operations on arrays; unsurprisingly, that’s true for hash tables, too.
Before jumping into the code, we are going to gloss over some theoretical aspects about this data structure because they are quite interesting, and fundamental if you want to get hash tables right.
In practice, there are two kinds of hash tables:
Chained Hash Tables
- Dynamic size. Can grow to accommodate more data.
- Data is stored in buckets.
- Solves collisions by putting colliding keys into the same bucket.
Open-Addressed Hash Tables
- Fixed size.
- Data is stored in the table.
- Solves collisions by probing the table.
Since at the time of this writing Ruby’s core team rewriting Ruby’s hash tables and switching from the chained variant to an open-addressed one. I decided to go with the later, but in most cases, any approach would do just fine.
Another important aspect about open-addressed hash tables is that (depending on the proving method) they offer better data locality, which is something that modern processor can take advantage off.
Hash Code
A hash code is a result to apply a hash function to a given key. While keys could be of any type, hash codes are always integers.
An important aspect to remember about hash codes is that they can collide. While proper hash functions are designed to produce as few collisions as possible, in practice they happen all the time. It’s entirely possible for a hash function to produce the same hash code for two different keys. It doesn’t matter how strong the function is; we should always account for collisions.
Probing methods
A proving method is an efficient way to find an empty slot for a given key in an open-addressed table. That’s it.
These are the most common probing methods:
Linear Probe
- Good cache performance.
- Easy to implement.
- Suffers from primary clustering.
Quadratic Probe
- Average Cache performance.
- Less clustering that linear probe.
Double hashing
- Poor cache performance.
- I don’t produce clustering.
- Need more CPU cycles.
Since double hashing is one of the most effective approaches (and also the one I’ll use in this post), let’s focus on that one.
Here is the definition for a double hashing function:
h(k,i) = (h1(k) + i * h2(k)) mod m

Double hashing function variables.
Considerations on hash functions and the number slots
To ensure that all positions are visited before any position is visited twice, we need to constrain the number of slots to be a prime number and design the secondary hash function to return a positive number less than the number of slots.
Another approach is to choose a number of spots that is a power of 2 and design the secondary hash function to return an odd number.
A typical auxiliary hash function for double hashing might look like (where k is the key and m the number of slots ):
let h1(k) = k mod m let h2(k) = 1 + (k mod (m-1))
Load factor
The load factor is the number of occupied positions relative to the whole number of slots in the hash table.
n = number of entries.
m = number of slots.
load factor = n / m.
Since open-addressed hash tables can’t contain more elements than slots, their load factor is less than or equal to 1. (The load factor for a full occupied table is 1.)
Keeping a healthy (below the average) load factor is crucial for open-addressed hash tables because as the table becomes full, the numbers of positions we have to probe increases drastically and make search operations costly and slow.
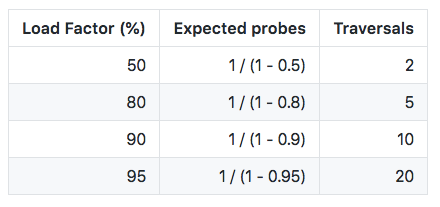
As you see in the table above, once the table’s load factor exceeds 80%, the number of positions we have to probe sends lookups performance to the dumpster.
A trick we can pull to keep a healthy load factor is to allocate the double of positions we expect to use. (Assuming you can sacrifice footprint for speed, doubling the number of slots is a good way to go.)
Now that we have reviewed the theoretical aspect of hash tables is finally time to jump into the code!
Hash Tables interface
The public interface of this data structure is dead simple; it only has an attribute and five methods:
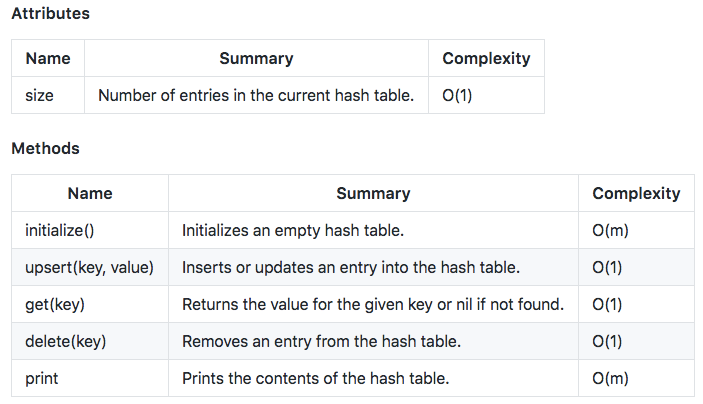
Hash Table interface. Methods names, summaries, and operations complexity.
Notice that after initialization, read and write operations run in constant time. (O(1))
Implementation details
While on from the surface hash tables are straightforward, implementation details are more complicated. Let’s start by taking a look at how entries are represented in the hash table.
Slot (hash table entry)

Slot members.
It’s important to note that we keep the original key for each table entry.
Now you may wonder: If we store entries by hashing their keys, why do we need to keep the original key?
To answer in one word, collisions_!_
While proper hash functions are designed to produce as few collisions as possible, in practice they still happen. So, when a collision occurs , the only way to “tiebreak” the hashcode is by looking at the actual key , and that is why we have to keep them.
Another reason for what we need the original key is for those cases where we need to rebuild the table.
So, now that we know how hash table entries look like let’s take a look at the hash table methods.
Initialize
This method is the hash table constructor and the one in charge of proper initialization.
These are the steps the constructor executes when we create an instance of a hash table:
- Set the initial number of slots to 5.
- Initialize all of the slots with nil values.
- Set up auxiliary functions, h1 and h2.
- Set size (occupied positions) to 0.
- Set the number of rebuilds to zero. (If the table grows past certain threshold we have to rebuild it.)
Since we have to initialize all of the slots in the internal storage, the complexity of this method is O(m).
def initialize
@slots = 5
fill_table @slots
@h1 = -> (k) { k % @slots }
@h2 = -> (k) { 1 + (k % (@slots - 1)) }
self.size = 0
@rebuilds = 0
end
*(If you are not familiar with Ruby’s syntax the code we use to configure h1 and h2 might look a bit odd, but that’s the syntax to define anonymous functions in Ruby.)
Upsert
This method inserts a new entry into the table or updates an existing one. Probably, this is the most complicated method in this data structure because it does a lot of things. (I know that this sounds bad, but believe me, in this case, is not.) Let’s analyze the code step by step.
The first thing we need to do is to check if there is already an entry for the given key. If there is one, we have to update the value and return.
If the entry does not exist, we have to check if there is enough room to add it to the table. If the number of slots is too small, we have to trigger a rebuild operation to ensure that the new entry fits into the internal storage. (Remember that in open-addressed hash tables the number of entries is fixed , if we need more room, we have to build it.)
Once we are sure that there is enough space, we have to hash the key and map it to a position into the internal storage. In our case, we do that by double hashing the key’s hash code until we find an empty slot or run out of positions. If the latter happens, the combination of hash functions we choose was to way too weak.
Notice that we use the key’s hash code and not the key itself. We do this because (internally) we need integer keys and Ruby’s hash method is a reliable way to get them. It doesn’t matter if users of this data structure use symbols or strings key, by using the hashcode we get the kind of values that we need.
Once we successfully mapped a key to a position in the internal array, we increase the table size and return.
Assuming proper hash functions and proper distribution, the complexity of this method is O(1).
def upsert key, value
if (slot = find_slot(key))
slot.value = value
return
end
rebuild if self.size > (@slots / 2)
0.upto(@slots - 1) do |i|
index = double_hash key.hash, i
slot = @table[index]
if slot.nil? || slot.vacated
@table[index] = Slot.new key, value
self.size += 1
return
end
end
raise "Weak hash function."
end
Get
Returns an entry’s value or nil if the entry doesn’t exist.
This method also applies double hashing to map a key to an index into the internal array. If there is an entry at the computed index, this method also checks the original key before return the entry’s value. (Remember that it’s possible for a hash function to produce the same code for two different keys. Unlikely, but entirely possible.)
As it happens with upsert , assuming proper hash functions and proper distribution, the complexity of this method is O(1).
def get key
0.upto(@slots - 1) do |i|
index = double_hash key.hash, i
slot = @table[index]
return nil if slot.nil? || slot.vacated
return slot.value if slot.key == key
end
nil
end
Delete
This method searches a slot that matches the given key and marks it as free if it finds it.
As it happens with upsert and get , the complexity of this method is O(1).
def delete key
find_slot(key)&.free
end
Find Slot
This method’s almost identical to get but instead of returning the entry’s value returns the entry itself.
While is not part of the public API, this method plays a critical role on this hash table because upsert and delete heavily depend on it.
The complexity of this method is O(1).
def find_slot key
0.upto(@slots - 1) do |i|
index = double_hash key.hash, i
slot = @table[index]
return nil if slot.nil?
return slot if slot.key == key
end
nil
end
This method prints the contents of the hash table. (Mostly for debugging purposes.)
The complexity of this method is O(m).
def print
@table.each do |e|
if e
puts "#{e.key}: #{e.value}"
else
puts "empty"
end
end
end
Rebuild
Rebuild is another core method that is not part of the public API, what this method does is to rebuild the internal storage when the table needs to make room for new entries.
In the code above PRIMES contains appropriate prime numbers of slots to use when doing incremental rebuilds.
(On production grade hashtables the maximum number of entries should be up to a couple of millions, but for demonstration purposes, I guess 509 is a reasonable limit.)
The complexity of this method is O(m).
PRIMES = [13, 31, 61, 127, 251, 509]
MAX_REBUILDS = 6 # Utmost equal to PRIMES.count
def rebuild
raise "Too many entries." if @rebuilds >= MAX_REBUILDS
old = @table
@slots = PRIMES[@rebuilds]
self.size = 0
fill_table @slots
old.each do |e|
upsert e.key, e.value if e
end
@rebuilds += 1
end
When to use hash tables
Hash tables work great when you can identify elements by unique keys, and you don’t need to traverse all entries sequentially. Caches, indexes, dictionaries, and routing tables are all good use-cases for hash tables.
Limitations
Since elements might be spread all over the place, hash tables should be avoided in situations where you need sequential reads (i.e., cursors.)
So, that’s it for hash tables. This post was a long one, and we cover a whole lot of ground. If you made it this far, is time to take a well-deserved break!
Next time, we are going to work with Sets. Stay tuned!
PS: If you are a member of the Kindle Unlimited program, you can read a bit polished version of this series for free on your Kindle device.

Data Structures From Scratch — Ruby Edition.