An Intro to Data Science at the Command Line with Pup, Go, and CLI Tools
This command line programming tutorial will teach you how to use command line tools to analyze data, including how to parse html with tools like Pup. Additionally, you will learn how to build a simple CLI (Command Line Interface) with Go.
This tutorial is based an office hours session hosted by Codementor Eric Chiang, the creator of Pup. Pup was on the top of Hacker News when it debuted.
The text below is a summary done by the Codementor team and may vary from the original video and if you see any issues, please let us know!
Nifty Command Line Tools You Should Try
Grep & nl
$Cat is a command line tool that will takes a file and spits out the content of the file.
grep will take the file and filter the content out.

The most important thing is the pipe (|), where we can take some command, take the output of the command, and put it into something else. So in this example we take the output of $cat, put it into grep using the command called pipe (|), and filter for the word “pup”. The cool thing about grep is you can have lots of pipes and chain the command together, like this:

nl basically takes every single line and puts the line number in front of it. In this case we have the $cat command line, cats_n_dogs.txt file, and in the middle we have the command line nl. We usually use this command to prepend the line number, which can be useful for huge text files where you want to search for a specific word, and now you can know the exact line number where the word is located.
Analyzing Data with the Pipe Command
Say you have a txt file containing all of Shakespeare’s work. Here are several command lines that will help you analyze the file:
\ $ cat Shakespeare.txt | \ sed -e 's/\s+/\n/g' | \
tr -d ' ' | \
grep -e '^$' -v | \
tr '[:upper:]' '[:lower:]' | \ sort | uniq -c | sort -nr | \ head -n 50in which you can find what were the most common words Shakespeare wrote with
\ sed -e 's/\s+/\n/g' | \sed replaces certain characters with other characters. In this case, white spaces and new lines are replaced, and every single word will be put on a new line. Then, you can trim the result with tr –d ‘ ‘ | \. Also, notice that the grep here
grep -e '^$' -v | \here is used in the opposite way of what it has been used for previously. Instead of filtering only for lines containing a certain word, here it will filter for any line that doesn’t use a particular keyword. In this example, we’re looking for any lines that don’t contain anything and filtering those out.
We can then convert every upper case letter to lower case with tr '[:upper:]' '[:lower:]', sort and count them with sort | uniq –c, sort them again and count them by numbers with sort –nr, and finally get the first 50 lines of the result with head -n 50
Curl & wget
wget has a tone of commands. For instance, it can take a link, downloads all its content, and save it to some file, like how I downloaded the text file containing all of Shakespeare’s works.
$ wget -O Shakespeare.txt \ http://gutenberg.org/cache/epub/100/pg100.txtOne of my favorite wget commands is
$ wget --load-cookies cookies.txtWhere I can load cookies, which signifies me as being a unique user to a website. (Eg. Facebook and twitter uses cookies to recognize users, and when I come back to those sites again it knows who I am based on my cookies.) wget can take these cookies and pretend to be me on a website, which is interesting because it will allow you to download in an automated, dynamic way that would not have been possible without the cookies.
The unfortunate thing about wget is that it’s not very pipe-like, so there’s another command called curl if you’re like me and really like using pipes.
Curl
Curl can also download files like wget:
$ curl -o Shakespeare.txt \ http://gutenberg.org/cache/epub/100/pg100.txtAdditionally, it can function like the $cat command.
$ curl http://gutenberg.org... | \ sed -e 's/\s+/\n/g' | \
tr -d ' ' | \
grep -e '^$' -v | \
tr '[:upper:]' '[:lower:]' | \ sort | uniq -c | sort -nr | \ head -n 50Therefore, instead of catting your files, you can use curl on a url to achieve the same results.
However it’s not easy to interact with HTML due to how irregular it is, even though it’s possible.
 this is what you’d get from google
this is what you’d get from google
What makes things worse, some horribly written HTML such as
<tbody>
<tr><img src="foo"></tr> <tr><img/><br>
</tbody> </table>
can be considered valid, but they cannot be parsed into XML, which just complicate things. All in all, my advice is to never try to write an HTML parser.
Instead, try using other tools like Python’s BeautifulSoup or Ruby’s Nokogiri. However, since both processes are kind of slow, I was looking for a better way to do this, and eventually stumbled upon a Go package html. It’s an awesome HTML parser someone has already written for you, and you can import it into your code.

However, I really want to be able to use it with pipes, which is where pup comes in.
What is Pup?
Pup is a command line tool for parsing html, and it was originally inspired by jq and Data Science at the Command Line’s idea of using command line tools to analyze data. It’s filled with tools that can take things like xml, json, and it can do interesting things with them very quickly, dynamically, and flexibly.
First we’ll use the command
$curl –s –L https://google.comwhich will spit out nasty html. But we can use pup to analyze it
$curl –s –L https://google.com | pup titleSo if you use the command pup title, all it will do is grab the title
<title>Google</title>
You can even filter for css selectors like the strong tag
$curl –s –L https://google.com | pup strong | head –n You can also filter for div ids to get a certain portion/element of a webpage like this:
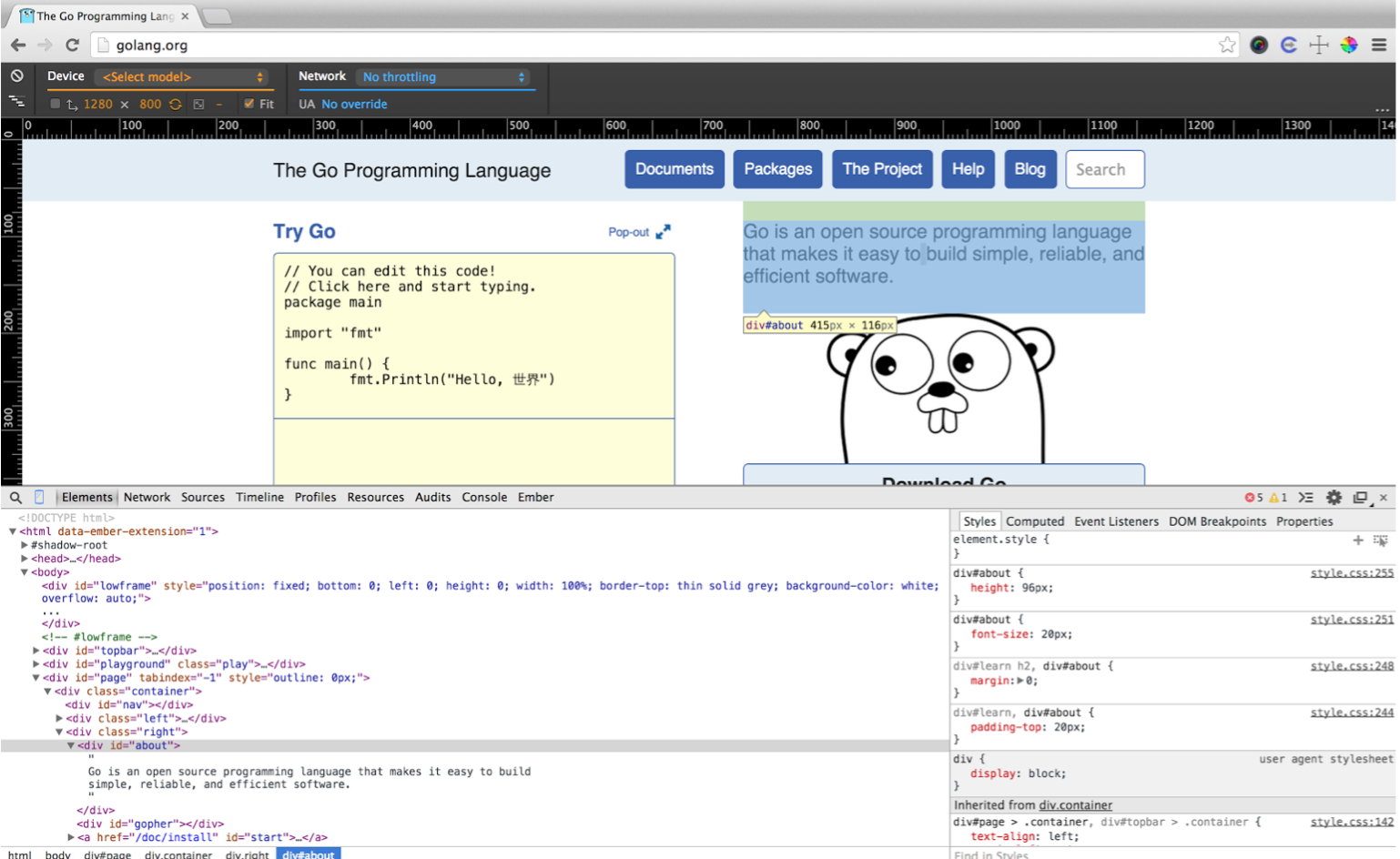 here we’ll grab the “about” section
here we’ll grab the “about” section
$curl –s –L https://golang.org | pup div#about
<div id="about">
Go is an open source programming language that makes it easy to build simple, reliable, and efficient software. </div>
However, in this example, pup is still spitting out html. It’s better than before, but still not optimal. So we can do a cool thing and spit out text instead with
$curl –s –L https://golang.org | pup div#about text{}
Go is an open source programming language that makes it easy to build simple, reliable, and
Which will just give us the text in the div.
Since you can chain pipe commands together, you can do some pretty intricate analysis of links.

For example, you can take sites like Reddit and YCombinator (HackerNews), grab all the top links on the websites (p.title for Reddit, td.title For HackerNews), grab children tags with a[href^=http], and then spit out the attribute itself to print all the top links using pipes.
You can also add json to make it even more consumable and get things like this:
$ curl -s https://news.ycombinator.com/ | \ pup td.title a[href^=http] json{}
[ {
"attrs": {
"href": "https:.../"
},
"tag": "a",
"text": "SHOW HN: pup"
},
... ]Building CLI tools with Go
import java.util.Scanner;
class Hello {
public static void main(String[] args) {
Scanner reader = new Scanner(System.in); System.out.print("Enter your name: "); String name = reader.nextLine(); System.out.printf("Hello, "+name+"!");
} }This is something like the first program I wrote in java in college. All it does is execute a program and it prints your name. Basically, the system.in and system.out is the same thing as stdin and stdout respectively.
Why Go?

Why not Java?
Java is a nice programming language, but you’d need java installed in your computer and not everyone has it installed, so it’s not optimal. Furthermore, Java can get pretty messy.
Why not Python?
Python is cool, and I’ve actually prototyped pup in Python initially, but again, Python needs an interpreter and people need to have Python installed along with the specific packages you’d need, such as Beautiful soup. Most of all it’s because of personal taste—I prefer Go.
Why not C?

There is actually an HTML parser in C called Gumbo, but C is pretty difficult for me, so it’s not the language I’d personally use. Go, on the other hand, is easier.
package main import "fmt" func main() {
fmt.Println("Hello, world!") }So this is what Go looks like as a simple hello world program. Packages are exactly what you think they are so don’t really worry about it. We’ll import the fmt, and print hello world.
To better illustrate how Go programs work, I wrote a little program called Line:
package main
import "io" import "os"
func main() {
io.Copy(os.Stdout, os.Stdin) io.WriteString(os.Stdout, "\n")
}Line will take some input from stdin, write stdout, and then append a line to it. You import a couple packages such as io and os. The first thing you’d do is copy stdin to stdout, and then write a string with stdout. And there, you’ve written a go program, or command line tool, that can do something interesting.
$ echo "Hello, World"
Hello, World
$ go get github.com/ericchiang/line $ echo "Hello, World" | line
Hello, WorldThis is what echo hello world looks like, and you can use go to get the line program, in which it will compile the line program and allow you to run it in your own computer.
GoX
GoX is a cross-compiler. For any of you who’s writing command line tools with go, I’d strongly recommend checking out GoX.

This is the release tool for pup—you can see it on github—and don’t worry about the bottom part, since it’s just messing with zip files. The important thing is this part:
gox -output "dist/{{.Dir}}_{{.OS}}_{{.Arch}}"Where it will build parallels like this:

The cool thing is that Go has no dependencies like Python and is completely runnable on other systems like windows.
Books to recommend on Command line tools:

Shell Scripting will get you the general gist of using command line tools in a linux and unix environment.

Data Science at the Command Line is also an excellent book that will teach you how to analyze data using the command line tool
Codementor Eric Chiang is a software engineer and founding member at Yhat, a NYC startup building products for enterprise data science teams. Eric enjoys of Go, data analysis, Javascript, network programming, Docker, and grilled cheese sandwiches.

