
Playing Tic Tac Toe using Reinforcement Learning
About me
I am an experienced data scientist and web developer with over 4+ years of experience. I specialize in using data analytics to help businesses make smarter decisions and thus help them scale. Moreover, I provide end-to-end website development services in order to help you establish an online presence and thus maximize your business's reach and expand your customer base. Additionally, I can help you integrate AI services into your stack regardless of the size of your organization. I always try to embed my applications with modern and minimalistic UI design principles which helps your customer correlate your brand with quality.
The problem I wanted to solve
I have always been fascinated by the amazing work done by OpenAI. The one that stood out to me was a AI bot that could play the massively popular game - Dota 2. Dota 2 used to be the escape from the real world for me and my friends while I was in high school. This inspired me to learn more about the field of RL. I wanted to start small so I started with Tic Tac Toe.
The process of building Playing Tic Tac Toe using Reinforcement Learning
’ Solving Tic-Tac-Toe with a bunch of code’. A keen viewer might note that I used the phrase ‘bunch of code’ simply because I didn’t want to focus on just the Reinforcement Learning techniques to solve the games, but also explore other, although inefficient, techniques such as Tree Search, Genetic Algorithms, etc. I would have loved to go for a more complex game like Chess, but being a beginner in the field, I decided to kill my ego and start with a game with one of the smallest state spaces — Tic-Tac-Toe.
Let’s take a look at our first gladiator:
1. The Minimax Algorithm
Minimax Algorithm is a decision rule formulated for 2 player zero-sum games (Tic-Tac-Toe, Chess, Go, etc.). This algorithm sees a few steps ahead and puts itself in the shoes of its opponent. It keeps playing and exploring subsequent possible states until it reaches a terminal state resulting in a draw, a win, or a loss. Being in any of these possible terminal states has some utility for the AI — such as being in a ‘Win’ state is good (utility is positive), being in a ‘Loss’ state is bad (utility is negative), and being in a draw in neither good nor bad (utility is neutral).
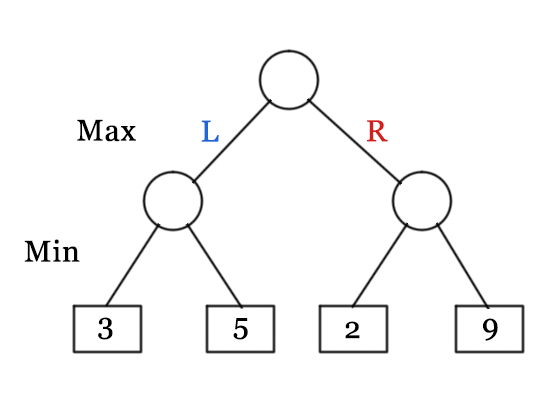
In our execution of the Minimax algorithm for solving Tic-Tac-Toe, it works by visualizing all future possible states of the board and constructs it in the form of a tree. When the current board state is given to the algorithm (the root of the tree), it splits into ’n’ branches (where n denotes the number of moves that can be chosen by the AI/number of empty cells where the AI can be placed). If any of these new states is a terminal state, no further splits are performed for this state and it is assigned a score the following way:
- score = +1 (if AI wins)
- score = -1 (if AI loses)
- score= 0 (If a draw happens)
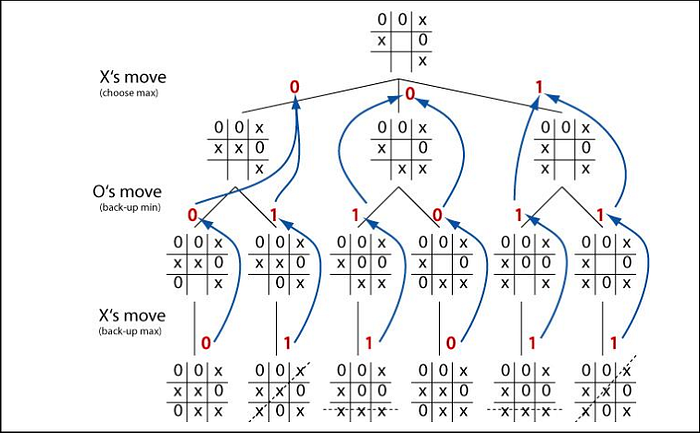
If, however, there are no terminal states — each of these new states are considered as new roots and they give rise to a tree of their own. But, there’s a catch — since this is a 2-player game and the players take turns alternatively, therefore whenever we go one layer deeper in the network, we need to change the player which would be placed in one of the empty cells. This way we can visualize what moves the other player would take as a result of our move. The algorithm evaluates the best move to take by choosing the move which has the maximum score when it is the AI’s turn and choosing the minimum score when it is the Human’s turn.
Code for Minimax Implementation
Since the state space of Tic-Tac-Toe is so small, we cannot have a tree with depth more than 9. Thus we don’t need to use techniques like alpha-beta pruning here. The thing with Minimax, however, is that it assumes a particular way of playing by the opponent. For example, a minimax player would never reach a game state from which it could lose, even if in fact it always won from that state because of incorrect play by the opponent.
Here is a sample game:
New Game!
----------------
| || || |
----------------
| || || |
----------------
| || || |
----------------
Choose which player goes first - X (You - the petty human) or O(The mighty AI): O
AI plays move: 2
----------------
| || O || |
----------------
| || || |
----------------
| || || |
----------------
Oye Human, your turn! Choose where to place (1 to 9): 3
----------------
| || O || X |
----------------
| || || |
----------------
| || || |
----------------
AI plays move: 9
----------------
| || O || X |
----------------
| || || |
----------------
| || || O |
----------------
Oye Human, your turn! Choose where to place (1 to 9): 5
----------------
| || O || X |
----------------
| || X || |
----------------
| || || O |
----------------
AI plays move: 7
----------------
| || O || X |
----------------
| || X || |
----------------
| O || || O |
----------------
Oye Human, your turn! Choose where to place (1 to 9): 6
----------------
| || O || X |
----------------
| || X || X |
----------------
| O || || O |
----------------
AI plays move: 4
----------------
| || O || X |
----------------
| O || X || X |
----------------
| O || || O |
----------------
Oye Human, your turn! Choose where to place (1 to 9): 1
----------------
| X || O || X |
----------------
| O || X || X |
----------------
| O || || O |
----------------
AI plays move: 8
----------------
| X || O || X |
----------------
| O || X || X |
----------------
| O || O || O |
----------------
Draw!
Wanna try again BIYTACH?(Y/N) : n
2. Reinforcement Learning
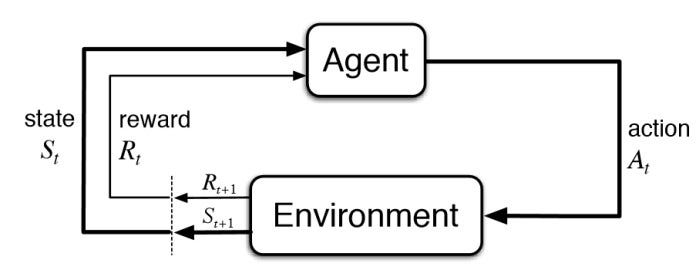
I feel like this algorithm is easier to grasp as you might be using this every day without even realizing it. Let’s take a practical example:
Say you are a dog owner. You pestered your spouse for months and finally got the little guy, but this furball(our agent) needs to potty train. The physical world where our agent can interact and well, go doodoo, is it's environment. The problem is simple — We want our canine buddy to do his business in the place we desire. But how do we tell it which place good or bad, without attempting to ‘talk dog’ and look stupid? Right, we use a reward system. Whenever our agent takes a dump on our fancy carpet, it gets a negative reward(calling him a bad boy, revoking a treat, a violent boop on the nose, etc). Whenever it takes a dump in front of our neighbour’s door who you find really annoying, it gets a positive reward(calling him best boy, his favourite treat, belly rubs, etc). Over time, the agent learns that whenever it wants to takes a dump(a particular state), it's better off soiling the neighbour's pavement than the precious carpet, as it would result in him being in a better state, the one which grants a positive reward.
Exploitation vs Exploration
One of the fundamental tradeoffs in reinforcement learning is the exploitation vs exploration tradeoff. Exploitation means choosing the action which maximizes our reward(may lead to being stuck in a local optimum). Exploration means choosing an action regardless of the reward it provides(this helps us discover other local optimum which may lead us closer to the global optimum). Going all out in either one of them is harmful, all exploitation may lead to a suboptimal agent, and all exploration would just give us a stupid agent which keeps taking random actions.
A widely used strategy to tackle this problem, which I have also used in my implementation, is the epsilon-decreasing strategy. It works as follows:
- Initialize a variable ‘epsilon’, with a value between 0 and 1 (usually around 0.3)
- Now with probability = epsilon, we explore and with probability = 1-epsilon, we exploit.
- We decrease the value of epsilon over time until it becomes zero
Using this strategy, the agent is able to explore better actions during the earlier stages of the training, and then it exploits the best actions in the later stages of the game. It’s kind of similar to how us humans function — We explore different options and seek new experiences in our early 20’s(exploration), and then we decide on a set career path and keep moving on that path(exploitation).
Temporal Difference Learning
The method of reinforcement learning used in this implementation is called temporal difference learning. It works on the principle that each state has a value attached to it. Say, if a state leads to the AI winning, it shall have a positive value(value = 1). If AI loses in some state, it shall have a negative value(value = -1). All the rest of the states would have a neutral value(value = 0). These are the initialized state values.
Once a game is started, our agent computes all possible actions it can take in the current state and the new states which would result from each action. The values of these states are collected from a state_value vector, which contains values for all possible states in the game. The agent can then choose the action which leads to the state with the highest value(exploitation), or chooses a random action(exploration), depending on the value of epsilon. Over the course of our training, we play several games, after each move, the value of the state is updated using the following rule:
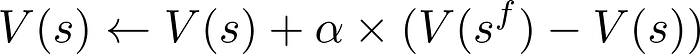
where, V(s) — the current state of the game board, V(s^f) — The new state of the board after the agent takes some action, and alpha — learning rate/ step-size parameter.
Using this update rule, the states that lead to a loss get a negative state value as well(whose magnitude depends on the learning rate). The agent learns that being in such a state may lead to a loss down the line, so it would try to avoid landing in this state unless necessary. On the other hand, the states that lead to a win get a positive state value. The agent learns that being in such a state may lead to a win down the line, so it would be encouraged to be in this state.
There are 2 versions of the code for this algorithm:
-
The testing code — You can play against the trained AI: Github Link
-
The training code — both the players are AI, where each of them helps train each other. This one is for my lazy squad out there. If you prefer grabbing some popcorn and letting the two AI fight it out among themselves, then here’s the code: Github Link
Following is a sample game against a bot trained for ~10000 epochs.
New Game!
----------------
| || || |
----------------
| || || |
----------------
| || || |
----------------
Choose which player goes first - X (You - the petty human) or O(The mighty AI): X
Oye Human, your turn! Choose where to place (1 to 9): 5
----------------
| || || |
----------------
| || X || |
----------------
| || || |
----------------
Possible moves = [1, 2, 3, 4, 6, 7, 8, 9]
Move values = [-0.218789, -0.236198, -0.147603, -0.256198, -0.365461, -0.221161, -0.234462, -0.179749]
AI plays move: 3
----------------
| || || O |
----------------
| || X || |
----------------
| || || |
----------------
Oye Human, your turn! Choose where to place (1 to 9): 1
----------------
| X || || O |
----------------
| || X || |
----------------
| || || |
----------------
Possible moves = [2, 4, 6, 7, 8, 9]
Move values = [-0.633001, -0.625314, -0.10769, -0.543454, -0.265536, 0.034457]
AI plays move: 9
----------------
| X || || O |
----------------
| || X || |
----------------
| || || O |
----------------
Oye Human, your turn! Choose where to place (1 to 9): 6
----------------
| X || || O |
----------------
| || X || X |
----------------
| || || O |
----------------
Possible moves = [2, 4, 7, 8]
Move values = [-0.255945, 0.003558, -0.2704, -0.25632]
AI plays move: 4
----------------
| X || || O |
----------------
| O || X || X |
----------------
| || || O |
----------------
Oye Human, your turn! Choose where to place (1 to 9): 2
----------------
| X || X || O |
----------------
| O || X || X |
----------------
| || || O |
----------------
Possible moves = [7, 8]
Move values = [0.0, 0.03941]
AI plays move: 8
----------------
| X || X || O |
----------------
| O || X || X |
----------------
| || O || O |
----------------
Oye Human, your turn! Choose where to place (1 to 9): 7
----------------
| X || X || O |
----------------
| O || X || X |
----------------
| X || O || O |
----------------
Draw!
Wanna try again?(Y/N) : n
Suit yourself!
It’s Showtime
Now that we have our 2 champions ready, let’s throw them into the virtual Colosseum and let them fight it out while we watch in awe. Since we just have 2 of them right now, we’ll just have a 1v1 TKO battle. Basically, this was the result:
Results(10 games):
Minimax Wins = 0
RL Agent Wins = 10
(I have summoned a monster, haven’t I?)
Final thoughts and next steps
If you wish to see the whole match, here’s the code: Complete Code
These are the only algorithms I have tinkered with yet. I might look into some other interesting algorithms like Genetic Algorithms, but that’s for later. If you found my writing remotely helpful or even amusing enough to make you chuckle slightly, throw a clap and drop a response below.
Thanks for reading ❤